
Avant de parler d’optimisation ou de pilotage par la donnée, une question préalable s’impose : peut-on réellement faire confiance aux données industrielles ?
Dans l’industrie des procédés, la réponse est rarement « oui ». Les informations issues du SCADA, des capteurs de terrain ou de tout autre système d’information sont rarement exploitables telles quelles. Signaux bruités, valeurs physiquement incohérentes, périodes manquantes, dérives capteurs non détectées : ces anomalies sont la norme. Tant qu’elles ne sont pas traitées, elles impactent direct sur la performance opérationnelle : du temps perdu à vérifier et nettoyer manuellement, des indicateurs calculés sur des bases instables, des décisions prises sur des informations partiellement erronées.
Avoir des données fiables est le prérequis de toute démarche de digitalisation sérieuse. Elle repose sur un processus structuré en 3 étapes clés : le diagnostic, la correction et l’automatisation.
Qu’est-ce que la fiabilisation des données ?
La fiabilisation de la donnée désigne l’ensemble des opérations visant à s’assurer que les informations collectées sont justes, cohérentes et représentatives de la réalité du terrain.
Le nettoyage des données, ou data cleansing, traite les erreurs de format, les doublons, les incohérences de saisie. La fiabilisation des données industrielles va plus loin en intégrant la compréhension du procédé en lui-même : sa dynamique, ses contraintes physiques, le comportement attendu de chaque instrument, d’où l’importance d’une double compétence en génie des procédés et en data.
Cet article se focalise sur les données quantitatives (numériques) comme celles issues de capteurs de température, débit, pression, niveau, composition, etc.
Pourquoi la fiabilité des données est-elle importante ?
Les enjeux de la fiabilisation des données dépassent largement la qualité technique des signaux. Ils conditionnent directement la performance opérationnelle, la conformité réglementaire et la pertinence de chaque décision.
- Prise de décision. Un opérationnel pilotant son unité via des indicateurs erronés prend des décisions fondées sur une réalité déformée. Cela mène à des ajustements contre-productifs ou à des dérives invisibles qui se traduisent par une baisse de performance.
- Performance industrielle. Des mesures de mauvaise qualité masquent les vrais leviers d’amélioration tant que les signaux ne sont pas validés : réduction des pertes, optimisation énergétique, diminution des arrêts non planifiés.
- Projets digitaux. Un projet d’intelligence artificielle ou de jumeau numérique construit sur des signaux bruts non fiables ne peut pas produire de résultats exploitables. La qualité des données est le premier facteur de succès, ou d’échec, de ces démarches.
Les anomalies les plus fréquentes dans les données procédés
Avant d’entrer dans le processus de fiabilisation, il est utile de nommer les problèmes courants :
- Signaux bruités : Le signal mesuré présente des oscillations rapides qui masquent la tendance réelle du procédé.
- Valeurs aberrantes : La valeur est physiquement impossible ou incohérente avec le fonctionnement du procédé, comme un débit négatif, une fraction massique supérieure à 100 %. Ce type de problème peut être le signe d’une dérive instrumentale, ponctuelle ou progressive, qui nécessite une vérification terrain avant toute correction.
- Lacunes d’acquisition : Des périodes de fonctionnement n’ont pas de valeurs à cause d’une perte de communication. Cela se traduit par une valeur constante, souvent zéro, ou NaN.
Quelles sont les étapes de la fiabilisation ?
Phase 1 : Le diagnostic
L’objectif est d’évaluer rapidement la qualité d’un signal et de déterminer s’il est exploitable tel quel, corrigeable ou à exclure temporairement. Cet audit repose sur quatre types d’analyses complémentaires.
- L’analyse statistique évalue la qualité brute du signal indépendamment du temps. La distribution est étudiée afin de détecter des mesures aberrantes, la présence de manque important de données identification des lacunes (NaN, zéros injustifiés) ou encore l’identification de plateaux min ou max synonyme d’un signal saturé.
Les outils visuels utiles à ce stade sont la boîte à moustaches (boxplot) et le diagramme en violon, qui donnent une lecture immédiate de la distribution et des outliers. - L’analyse temporelle contrôle la cohérence temporelle vis à vis de la dynamique du procédé et la fréquence d’acquisition des données. Elle permet également la détection de pics isolés ou d’anomalies récurrentes (bruit périodique, cycle jour/nuit).
Le graphique temporel, avec une éventuelle superposition des signaux, est utilisé. - L’analyse métier vérifie que les mesures respectent les lois physiques et la cohérence avec le fonctionnement du procédé. Les phases transitoires (démarrage, arrêt, nettoyage, changement de régime) sont particulièrement utiles.
Les calculs métiers, comme les bilans matières et thermiques ou encore la cohérence de l’état physique par le couple pression-température, sont utilisés. - L’analyse des capteurs est réalisée si un signal est jugé suspect. Cette étape permet de remonter à l’origine du dysfonctionnement et de le résoudre. Pour cela, la plage de mesure nominale est vérifiée afin d’écarter un problème de saturation du signal. L’historique de maintenance est également examiné afin d’identifier des interventions récentes. Une calibration peut également résoudre un décalage des valeurs. Les résultats peuvent également être comparés avec une mesure indépendante.
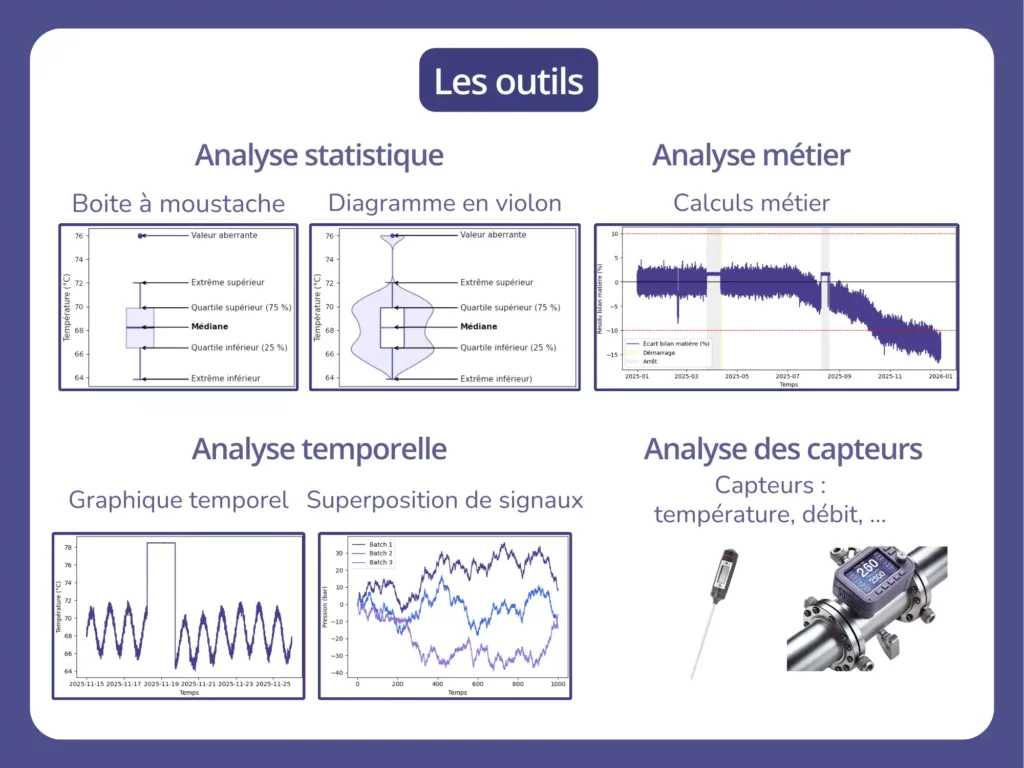
Les outils utilisés lors de l’étape de diagnostic pour la fiabilisation des données
Phase 2 — La correction
Une fois le diagnostic établi, la correction consiste à supprimer les valeurs aberrantes et à gérer les valeurs manquantes. Le choix de la méthode dépend de deux facteurs : l’origine du problème identifiée lors du diagnostic et l’objectif d’utilisation des données.
Voici quelques exemples de corrections fréquentes :
- Un signal bruité est lissé par une ou plusieurs techniques, comme la médiane glissante, le filtre passe-bas ou encore le filtre de Savitzky-Golay. Le choix de la fenêtre de lissage doit être cohérent avec la dynamique du procédé. Ainsi, le signal traité devra être validé afin de vérifier qu’il respecte la tendance initiale du signal.
- Les valeurs aberrantes sont retirées. Selon le contexte, elles peuvent être remplacées par interpolation, ou simplement exclues de l’analyse. Si l’aberrance est systématique, la cause est probablement instrumentale et nécessite une intervention terrain.
- Les valeurs manquantes ou supprimées peuvent être imputées par des méthodes classiques comme la moyenne ou la médiane. Dans l’industrie des procédés, il est préférable d’utiliser des calculs métier, comme les bilans matières et thermiques, pour reconstruire une valeur manquante.
- L’hétérogénéité temporelle est traitée par un rééchantillonnage pour synchroniser les données issues de systèmes différents. Ce traitement permet de ramener tous les flux à un pas de temps commun. Cela est nécessaire pour croiser les mesures et effectuer des calculs cohérents, qui seraient impossibles avec des horodatages décalés.
Phase 3 — L’automatisation
L’automatisation a pour objectif de pérenniser la fiabilisation, en détectant et corrigeant automatiquement les données. Elle facilite la gestion en continu des règles de correction définies lors de la phase de correction. Les étapes de l’automatisation sont :
- Appliquer en continu les règles de correction définies en phase 2
- Confronter régulièrement les résultats au terrain et ajuster les règles si nécessaire
- Mettre en place une détection d’anomalies en continu (seuils d’alerte, surveillance des bilans, comparaison entre capteurs redondants)
- Documenter chaque modification pour assurer la traçabilité et l’appropriation par les équipes.
Quels outils pour la fiabilisation des données industrielles ?
Le choix de l’outil dépend du niveau de maturité digitale de l’usine et du volume à traiter.
- Python est l’environnement de référence pour construire des pipelines de traitement sur mesure, adaptés aux spécificités de chaque procédé.
- Les plateformes de données industrielles, comme OIAnalytics, Seeq ou encore OSIsoft PI, facilitent la fiabilisation dans un environnement no-code : visualisation des signaux, création d’alertes, calculs métiers. Mais elles nécessitent toujours de paramétrer les règles métier adaptées au procédé.
Conclusion
Fiabiliser les données industrielles, c’est le prérequis de toute démarche de digitalisation sérieuse. La mise en œuvre de cette méthode en 3 phases permet d’aborder la qualité des données de manière structurée, en s’appuyant sur la connaissance des procédés ainsi que les outils d’analyse de données.
La rigueur apportée à cette étape conditionne la fiabilité des données utilisées ensuite : les tableaux de bord, les KPI, les modèles et in fine les décisions prises par les équipes opérationnelles.
Améliorer la qualité des données, c’est réduire les erreurs de pilotage, détecter les dérives plus tôt et sécuriser les projets de digitalisation. C’est aussi libérer les équipes des corrections répétitives, pour qu’elles se concentrent enfin sur l’analyse et la création de valeur.
Vous souhaitez évaluer la qualité de vos données procédés ? Contactez-moi pour un échange sur vos enjeux de fiabilisation.


